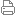
|
Dorothycuct
2025-10-7 15:44:50
显示全部楼层
| |




XSP18 支持从充电器/充电宝等电源上取电给产品供电, XSP18 芯片集成 USB Power DeliveryPD2.0/3.0 快充协议、 QC2.0/ ...

通过网盘分享的文件:C4D中文安装包及教程资源 链接:https://pan.baidu.com/s/1afuU-M4OOyt8KWScivhNIA?pwd=1557 提 ...




根据数据机构 Counterpoint Research 公布的数据,第三季度的手机市场份额出现了较大变化,vivo和OPPO份额占比均超20% ...


#现在的大学生玩什么端游##帝国时代##帝国时代3#【帝国时代3征服战X王者荣耀|天苍苍野茫茫风吹草低现苍狼##元明清##成 ...









bot虽然都是枪枪头大师,但某些地方是真的心态崩了。 1.更新前根本不拿资源,更新后nm每个资源包都拿,然后瞎jb分配, ...



3月27日讯 据阿根廷媒体mundoalbiceleste报道,达米安-马丁内斯在接受采访时表示,如果能够卫冕世界杯,他就会从阿根 ...


苹果 15 puls256g 粉色 电池 90% 自用 屏幕完好 无维修 功能正常 24 年 5.20 购买 没过保 先挂着手机粉色比较适合女生 ...


在云拼接控制器领域,东健宇电子、景阳华泰科技、东健智能、达强科技、济南东建宇 TECHING 等厂家凭借各自优势占据市 ...


微软似乎正在悄悄地为 Copilot 建立一个新的白板风格的工作空间,泄露的截图显示,这是一个成熟的人工智能驱动的白板 ...

智能云:增长核心引擎 · Azure业务:2025财年全年营收超750亿美元,同比增长34%。2025财年Q4 Azure增速39%,AI服务是 ...


GEO英文全称:Generative Engine Optimization,中文译为:生成式引擎优化或AI搜索优化。GEO的核心逻辑:按照生成式引 ...




广州川博科技是智能商用设备领域的头部生产企业:位于中国广州番禺行业中心,拥有1万平米的生产基地,多个厂区分布( ...






这个配置,耐久性,稳定性和性能应该是目前最喜欢的配置了,没有之一! DELL 3050mff小主机: i5-7500T 低功耗处理器 ...
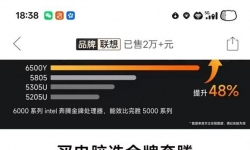
紧急求助sos 奔腾Gold 6500Y 处理器,双核心四线程;显卡:Intel UHD Graphics 615; 运行内存:可选16G/32G; 硬盘内 ...


看到相关文章,发现MBP是可以合盖不休眠的,有以下软件KeepingYouAwake,Insomniax(第二个没找到资源,如果你知道哪有 ...



我ps5pro连接qd-oled的显示器,常驻hdr,显示效果一直很好。今天用4070的笔记本连接了一下显示器,hdr设置了半天,该 ...


快科技3月9日消息,马克・古尔曼爆料称,苹果计划2026年推出全新的MacBook Ultra机型。 这并非此前传闻的M6系列MacBoo ...

二手东风多利卡2吨蓝牌油罐车,四川达州户2020年5月份上的牌照/广西桂林户2017年的蓝牌油车/贵州户5吨黄牌油车/河南南 ...


USB9314是阿尔泰科技的一款USB总线多功能模拟量输出模块,该模块支持8路模拟量同步输出,16位DAC分辨率,转化速率高达 ...



今天(3月10日)凌晨,苹果正式向开发者推送iOS 26.4 Beta 4开发者测试版系统,具体推送版本如下:iOS 26.4 beta 4(23 ...



有一辆很老的26要装起来,所以鱼上收点老物件,因为对marzocchi这个牌子很有好感,直接盲狙了这根m2 comp。但我对marz ...


在2026年,面对众多显示器选择,很多消费者感到困惑:哪款才是最值得购买的?作为一名专业评测员,我经常收到关于显示 ...






 微信扫一扫
微信扫一扫