| |
|
ChiWongsuig
楼主 2025-10-16 17:20:54
显示全部楼层
| |
|
ChiWongsuig
楼主 2025-10-16 17:21:10
显示全部楼层
| |
|
ChiWongsuig
楼主 2025-10-16 17:22:28
显示全部楼层
| |

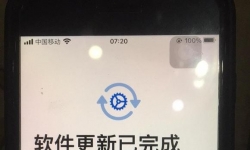
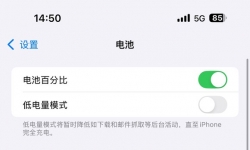
一个经常使用的8P,系统是13.7,手机更新到了ios16.7.14,长期追踪使用感受 因屏蔽自动失效,早上起来发现手机自动更新 ...

点击查看→#小程序://贝壳找房买房房价租房新房二手房/崧泽华城青湖苑精选房源/GVTKtrY4DMgRRex ⭐⭐整租·崧泽华城青 ...










7.8米行车梁出售:650高X上350/16X下220/16*8立筋,32支,江阴提,电话18901565588 ...









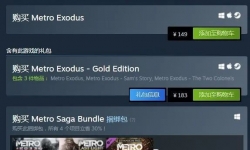
据Steam商店信息显示,《地铁:离去》在Steam商店售价现已永久降低。标准版由199元降至149元;豪华版从298元降至183元 ...

2026年高级经济师已经进入最后冲刺阶段,酷舍网为你从网上搜集整理了2026年高级经济师电子书pdf汇总百度网盘分享免费 ...



游戏时间站(yxsjz.cn) 海量优质Quest游戏分享,大量热门steamvr游戏下载!更有众多优质汉化vr游戏推荐 ...



2020年4月体检发现左下肺外基底段有一0.7x0.6cm结节,医生诊断良性让随诊,2021年4月另一医院CT检查直径0.5cm。目前患 ...


这里只放可以一定不会被封的 贴一些b链【萝莉!!!白丝!!!蓝白碗!!!】 https://www.bilibili.com/video/BV1fcpBz1Esg/?s ...





耳机主流型号及对比 苹果 AirPods Pro 三代耳机 洛达1562A芯片,ANC 35DB真降噪👉🏻改名、真降噪、三真电量、不跳电、 ...



淡季冲击 14promax 1TB价格奔盘别买贵! 15新品价格经过三连跳,可以说彻底崩盘了 新款手机大降价,老款手机自然扛不住 ...







悦虎的AirPods四代升级了最新固件,他这里有最新的三代四 帮我看看AirPods四代是翻车了嘛?我升级了固件 来自:tieb ...


 微信扫一扫
微信扫一扫