| |
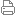
绝缘栅双极晶体管(IGBT)作为兼具MOSFET电压控制、低驱动功率与BJT低饱和电压、高耐压特性的功率半导体器件,广泛应 ...








众神之怒更新索林一直没玩,最近看到灾厄大更新想着正好打一打,但是发现tmod突然打不开了 ,之前玩的时候一直没有问 ...



销量口碑双丰收,市场选择彰显实力 咪鼠AI键盘能在抖音官旗创下5w+销量、98%好评的佳绩,绝非偶然。这份亮眼的市场成 ...


成毅,你演技真的很棒。成毅的演技总能让人感到温暖和舒适。成毅:“我重新思考了执着、努力、遗憾、放下,它们会一直 ...


iPhone12pro,ios14.4.2,uncover7.0.2安装完成,但是显示unsupported,为什么?试了好多次,重启了好多次,都是这样 ...


撒贝宁 2026年2月4日,马年央视春晚的主持人名单正式曝光,北京主会场有6位主持人,分别是:撒贝宁、任鲁豫、尼格买提 ...

没加盖子的后果,以为留了10cm水位就不会越狱,昨晚3点半黑夜中摔去小角落里,也不知道多长时间,好在把我蹦哒醒了把 ...
IT之家 3 月 11 日消息,消息源 Kosutami 今天(3 月 11 日)在 X 平台发布推文,透露苹果智能家居中枢(HomeHub 或叫 ...

众所周知,苹果计划在今年推出首款折叠iPhone,距离发布还有6个月左右时间,现在又有3D CAD渲染文件曝光了。虽然现在 ...

歌曲目录: 1.和天一样高 C5 2.你是我真心的执着 F5 3.蝴蝶结 E5咬字 4.我的心在发烫 G5 5.河 A5 6.She's gone(中文版 ...
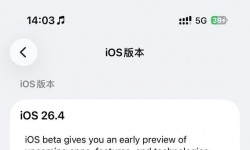
前几天苹果才推送了 iOS 26.4 Beta 3,现在非常意外又紧急推送了: ■iOS 26.4 Beta 3 v.2■iPadOS 26.4 Beta 3 v.2■ ...

这届iPhone13promax,请问是温感屏幕吗,认真的吗库克#Iphone13promax发绿##苹果发绿# 换个两台都是如此,G9N,上海发 ...


在显示器技术日新月异的今天,OLED面板早已凭借其深邃的黑场与极速响应占据高端市场。然而,第一代QD-OLED在文本彩边 ...
买什么13买什么13pro或者max,你买一部ipadpro2021他不想吗?13迷你和标准版还没有高刷,pro和max支持120自适应高刷, ...







目前越来越多的爆料都指向iPhone17 PM的背面设计会大改,变成横排三摄[lbk]暗中观察R[rbk]背面用了这么多年的外观总算 ...

问题发现两三个月了,每次更新系统都不见更新这个问题,很无奈,不知道是不是个例,平时比较忙,没什么空跑客服中心去 ...

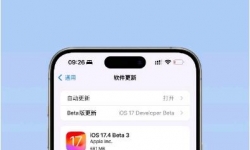
苹果突然宣布停止签署iOS 18.0,升级后的你还想降级吗? 近日,苹果公司做出了一个重大决定,那就是正式停止对iOS 18. ...



UTM SE最近上架了App Store 使得对UTM SE的安装变得简单许多 所以出一期关于UTM SE的常见问题解答 前言: 在iOS/iPad ...

Biwin Intelligence 今年才出的固态存储管理软件 带固件更新功能 仅支持win10 win11系统 佰维官网明确表示支持佰维旗 ...

土区自己开的车,香港IP有可能用不了。不提供上网方式,机场需自备,独立账号,独立PIN,还差2个位置,来2个长期车友 ...

据行业机构发布的《2025移动电源安全技术趋势报告》显示,用户在选购充电宝时最关注的三大因素已从“容量、价格、体积 ...

老pad,12的系统,一直挺稳定,最近有的app在12下不给升级了,现在系统更新那边直提示 只能连电脑升级16,请问能否升 ...

给了限时优惠券把价格压到那么低,还是首发,友商还没促销,昨天当天销量也只有第三吗?昨天发布会不是说魅族AR眼镜国 ...


🚀 核心功能更新 ✨ imgs_infos接口重大升级 🎨 支持多个入场动画参数(in_animation)用|分隔传入 🔄 支持多个循环动 ...

《最终幻想7:重制版》和续作《重生》获得成功之后,SE社区开始讨论《最终幻想》下一步作品。重制《最终幻想6》和《最 ...

国行7209机型ps4pro,8.5的版本,双手柄,送三张游戏鬼泣5、全境封锁、风之旅人。包邮1750元,买家标注吃灰几个月了, ...





开罗游戏大合集62款 62款合集礼包(KAIROSOFT COLLECTION GAMES)免安装中文版 关于这款游戏 集齐开罗游戏历史上开 ...
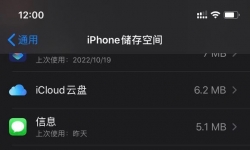

前几天在海鲜市场买了个白色的5c 到货后我发现系统还在iOS7.1.2而且还越狱了,于是我进Cydia看了一下,居然有目前网上 ...

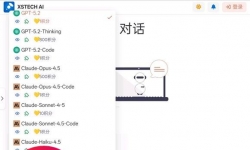
半公益站目前可用服务 对话:GPT系列模型,Claude系列模型,Gemini系列模型,Grok系列模型,Llama系列模型,Deepseek ...








 微信扫一扫
微信扫一扫