| |

vivo在国内销量十分火热,深受国内用户的喜爱!特别是得到了国内女性用户的青睐!都说vivo的手机设计唯美,发布有些时 ...


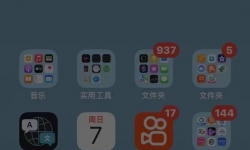
#进吧必看# 慧联A10 Airpods3rd 1: 慧联247 +真光感+真压感(玻璃压感) 2:EO智能自适应调节,原装音质3:双6轴 ...



电脑为macbook pro 2019cpu i7gpu radeon pro 550x支持bootcamp,以前一直作为纯windows电脑使用,为更新显卡驱动启动 ...

城阳专业投下水道抽污水电话 0532-6663-5353 专业CCTV管道清淤检测,管道高压清洗疏通,156-6652-1215 化粪池隔油池清 ...


城阳市政管道清淤电话0532-8888-9866专业疏通管道抽污水131-7653-7327 城阳专业清洗疏通管道,气囊堵水,抽淤泥,管道 ...


亲,12日单,长期收售,置换,安全,爽快可刀; ¥1000国际服顶尖6光暗帝史龙泰锤苹史莱姆萌王朱菜拉姆兰蒂水扇水尼水 ...






云南范围AI智能外呼电话,有效的帮助电销公司联系客户,寻找到有意向的客户,帮助企业节省人力物力,省心省力直接对接 ...

说说大家为什么说终于等到了,华为手机是5G先锋,在2020年以前,华为大力推出5G手机,但到了2021年,华为遇到了不少困 ...

k60这手机续航没话说,1080p+120hz,亮度一半,双卡双待4g,8小时亮屏还是很轻松的,就降压➕潘多拉内核,啥都没用, ...

在追求长久健康与巅峰状态的时代,科学抗衰已成为许多人的必修课。NMN作为支撑细胞能量的关键成分,无疑是社会关注焦 ...

深潜 #成毅深潜##成毅云弘深# 深潜 云弘深 成毅演的真好,真帅 #成毅深潜#成毅,你真的很优秀,很棒,你是个好演员 ...



前职业选手Afoninje在直播中认为Yatoro仍有动力冲击更多荣誉,他观赛了Nigma在裂变天地S1西欧区预选的失利后发表了这 ...

废旧电脑、打印机、复印机、硒鼓、墨盒、电脑散件,ups、线路板、电线、网线、电瓶、空调、稳压器、 变压器、各种金属 ...







挂个号b站 ios wsm 42/84ssr 6宝摩根 5宝水尼禄 宇宙凛 暗狐 奥伯龙 2.7打完后面没玩了 后面的活动从者都没,礼装 ...

Devil Toys x Quiccs TEQ63 ONIMARU 鬼丸 1/12手办,在bang购全新未拆封,和自己玩具风格不是很搭,限量199体,全新降 ...









本公司长期收购 空调,中央空调回收:(1-1000匹)挂式空调、柜式空调、吸顶式空调,窗式空调,圆柱式空调,钳 ...

【联东U谷-通州永乐产业园区】——规模300亩 联系人:马令令 15811168163 出租 底商:面积:97平米、110平米、200平米 ...









还在苦苦寻找一款小巧又好用的洗内裤专用洗衣机吗?2026年最新发布的十大高性价比迷你机型权威榜单终于来了!不管是宿 ...



纯美术用途,这个SURFACE的笔真的太难用了。 IPADPRO的手感接近WACOM,甚至好于WACOM SURFACE的这个笔,真的是一言 ...


在“健康中国 2030”战略的强劲推动下,大健康产业正迎来爆发式增长。《中国大健康产业发展报告(2023)》明确指出,2 ...

苹果 2026 春季新品发布会前瞻 与 iOS 26.4 系统升级详解 body{margin:0;font-family:-apple-system,BlinkMacSy ...


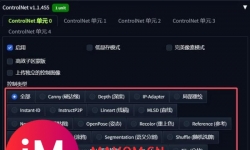
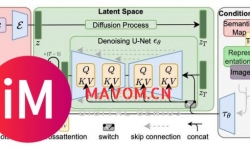


什么是Stable Diffusion?一文带你区分 Diffusion,Latent Diffusion和S... ...



 微信扫一扫
微信扫一扫