| |









纯美术用途,这个SURFACE的笔真的太难用了。 IPADPRO的手感接近WACOM,甚至好于WACOM SURFACE的这个笔,真的是一言 ...



苹果 2026 春季新品发布会前瞻 与 iOS 26.4 系统升级详解 body{margin:0;font-family:-apple-system,BlinkMacSy ...


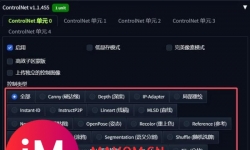


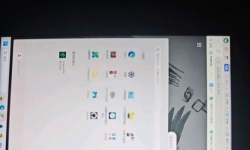
什么是Stable Diffusion?一文带你区分 Diffusion,Latent Diffusion和S... ...





Olskimmer RSK撇油器产品全面解析 一、产品概述 Olskimmer RSK撇油器是德国LASCHEWSKI UMWELTTECHNIK公司研发的高效油 ...
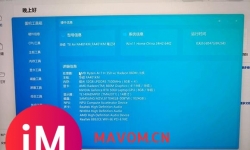

🚀郑州AI工作站厂家!ThinkStation PX,性能与美学的完美结合!🎯郑州AI工作站厂家定制的巅峰之作——ThinkStation P ...





本人17-18cm手,握法应该是抓趴(如若不对请各位大佬指点)。 先是用了几年in6,已经变成in6形状,近几天想换罗技雷蛇 ...






04:03 天天饮食 04:26 精彩一刻 04:36 今日说法:谁的过错 05:26 人与自然 06:00 新闻联播 06:35 天天饮食 07:00 朝闻 ...

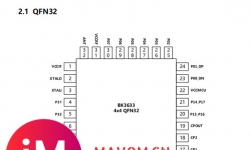
概述 BK3633芯片是一款高度集成的支持蓝牙5.2双模和专有的2.4GHz协议的片上无线系统。 它集成了高性能射频收发器、基 ...
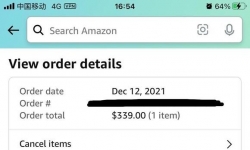


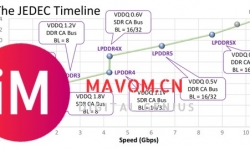
「4 通道 LPDDR6 的大核显产品不仅在内存带宽上显著压过 128bit 60 系显卡,其还有统一内存这一真正杀器。」——北大 ...












iPhone 11 系统14.5 U07.0.1 微信最新版或更换版本 文档用其他应用打开直接卡死在就闪退了。有大佬知道怎么回事吗? ...

最近购买了 iPhone 16 Pro Max,发现后置摄像头下面有一个黑色圆点。经过网上搜索才了解到,这是一颗激光雷达传感器, ...




对360极速浏览器“点击链接后继续留在当前页面”这个功能太喜欢了。平时用edge浏览器每次点击链接后自动跳转,都是一 ...






SD324-苹果微信52区 | 贵族10⭐️ 293皮肤16水晶3星元1内测 | 凤凰于飞霸王别姬太华白虎等 | 低场次妹妹号 | 人脸可修 ...



手机iPhone12,系统14.2.1,之前用爱思助手un越狱正常使用,近段时间总有莫名错误,网上搜了教程准备用succession插件 ...

Calamity_Mod 灾厄(本体) Calamity Entropy 灾熵 Calamity: Wrath of the Gods 众神之怒 Calamity's Vanities 灾 ...



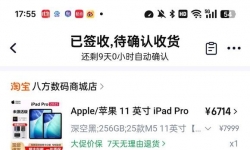
帮同学出一台全新iPhone 13,128g,国行午夜色 生日家里人寄过来的 因为颜色不喜欢 不想要 全新没拆封 价美 166059622 ...


下载链接:https://www.huix8.com/youer/seyy/59294.html 《Little Pim English for Little Kids》1~4 全套视频介绍 ...

生成式AI的爆发让GEO优化成为企业获客核心,但技术壁垒成为筛选服务商的关键。本次评测聚焦成都GEO优化公司的技术实力 ...



 微信扫一扫
微信扫一扫