| |
,mjlq2的,二手,看到是2016.9.21第一次激活 在淘宝上一个挺大的店铺买的,貌似有好几千个好评 缺点: 对比了一下原 ...







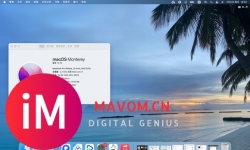
新站区地铁四号线首发站 力高大发君御天下 8层真洋房工抵房底复产品 7#105 178平121万 5#106 208平133万 上下面积对 ...



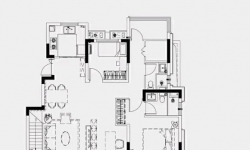
新站区地铁四号线首发站 力高大发君御天下 8层真洋房工抵房底复产品 7#105 178平121万 5#106 208平133万 上下面积对 ...




watchOS 拟融入 visionOS 设计,Apple Watch Ultra 或配专属芯片_百度知 ... ...












极摩客 M5 Ultra 尺寸128.8×127×47.8 (mm),体积不到 0.8L,采用双风扇散热系统,支持最高 35W 性能释放(TDP 可在 ...



华硕ROG Strix OLED XG27UQDMS显示器现已正式上市。 该产品整体尺寸为611 x 169×503mm,净重约6.1kg。其核心配备了一 ...


快科技3月12日消息,随着iPhone Fold生产节奏的不断加快,苹果已向三星大批量订购了12GB LPDDR5X内存,这一举动预示着 ...














南京硬盘数据恢复_季先生金士顿1GB U盘不识别数据恢复成功 客户单位:季先生金士顿1GB U盘不识别数据恢复成功 设备: ...





















苹果公司今日凌晨发布了最新 iOS 26 beta 4版本,版本号: 23A5297i 。其主打的 Liquid Glass 玻璃美学设计便成为众人 ...











 微信扫一扫
微信扫一扫