| |












齐齐哈尔斗山NHP8000机床钣金防护罩 齐齐哈尔斗山NHP8000钣金防护罩创新设计:庆云金恒兴的匠心突破 在重型数控机床领 ...






用了三个月的AirPods Pro不幸掉了右耳,找不到了。准备小黄鱼买一只二手的配一对。 看到好多卖家都有大批量的二手airp ...




最新版chrome在启用--force-renderer-accessibility浏览页面时会崩溃, 错误代码:STATUS_BREAKPOINT ...




救救孩子吧 iPad密码错误太多次停用了 显示连接iTunes 我按照百度流程连接了 点更新提示我iTunes不是最新版本需要更新 ...

✨2025 美国产业用布及纺织品展,Advanced产业布年度盛会来袭,不可错过,冲鸭! 各位产业布行业的从业者们👋,今天 ...

蝙蝠最新版本Android&iOS 3.5.0已上线(可至官网下载https://www.batchat.com) 主要更以下功能: 一、新增水印相机功 ...




苹果在上周发布了iPhone 17e和MacBook Neo等新品,但是备受期待的HomePod mini以及新款Apple TV一直没有出现,现在有 ...






ZB家的货,一个手柄没反应导致主机不能激活进入系统。 寄回换货,昨晚商家发来他们的测试视频 视频里显示他们使用手柄 ...

🚀 核心功能更新 ✨ 重构视频云渲染功能,达到可上生产环境标准 修复所有素材类型Transform坐标计算错误:统一使用草 ...

photoshop 2021 for mac 在M1上导出Png时,会提示“发生了未知错误”,即使点击“导出”按钮,导出的图片也是一个空白 ...





#iPhone#召回的政策还是很好,但是去售后服务中心ios14的系统检测不了,需要升级到ios15才能检测,内心真的不能接受升 ...
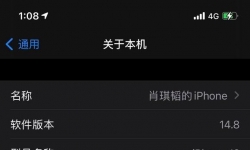

Omni Recover macOS可以让你检索被删除的消息、照片、WhatsApp聊天,等等,无论你已经达到了什么阶段。 不管原因是什 ...
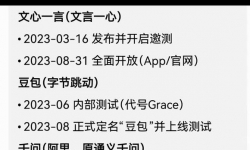





箱说齐全 1950sfby,送一根同轴线啦 这款用料挺好的,箭猪的环牛 全彩屏幕支持AirPlay2,网线wifi 投送能显示歌词封面 ...

⚠️10几万,稀有车型 16奔驰CLS350 黑武士外观 4座 黑外黑内(宝石蓝贴黑膜) 7速波箱 V6机头 无框车门 后驱操控王 ...










【CNMO科技消息】随着iPhone 17系列及iPhone Air的发布,苹果调整了其产品线,停售了iPhone 15和iPhone 15 Plus,并将 ...








 微信扫一扫
微信扫一扫